搜索到
10
篇与
其他
的结果
-
 PHP如何使用 ElasticSearch 做搜索 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。在做搜索的时候想到了 ElasticSearch ,而且其也支持 PHP,所以就做了一个简单的例子做测试,感觉还不错,做下记录。环境php 8.0elasticsearch 8.2elasticsearch-php 8.2安装 elasticsearch下载源文件,解压,重新建一个用户,将目录的所属组修改为此用户,因为 elasticsearch 无法用 root 用户启动。wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3.tar.gz tar zxvf elasticsearch-8.2.3.tar.gz useradd elasticsearch password elasticsearch chown elasticsearch:elasticsearch elasticsearch-8.2.3 cd elasticsearch-8.2.3 ./bin/elasticsearch // 启动安装 PHP 扩展我这里使用的是 composer 安装 elasticsearch-php。在 composer.json 文件中加入 "elasticsearch/elasticsearch": "~8.2.3",执行 composer update。{ "require": { // ... "elasticsearch/elasticsearch": "~8.2.3" // ... } }测试例子创建表和测试数据我这里准备了一张文章表来进行测试,首先是建表,其次写入测试数据,准备工作完毕之后,就开始编辑测试用例。{ #创建articles表 create table articles( id int not null primary key auto_increment, title varchar(200) not null comment '标题', content text comment '内容' ); #插入文章内容 insert into articles(title, content) values ('Laravel 测试1', 'Laravel 测试文章内容1'),('Laravel 测试2', 'Laravel 测试文章内容2'),('Laravel 测试3', 'Laravel 测试文章内容3'); 从 Mysql 读取数据try { $db = new PDO('mysql:host=127.0.0.1;dbname=test', 'root',''); $sql = 'select * from articles'; $query = $db->prepare($sql); $query->execute(); $lists = $query->fetchAll(); print_r($lists); } catch (Exception $e) { echo $e->getMessage(); }实例化require './vendor/autoload.php'; use Elasticsearch\ClientBuilder; $client = ClientBuilder::create()->build();名词解释:索引相当于 MySQL 中的表,文档相当于 MySQL 中的行记录elasticsearch 的动态性质,在添加第一个文档的时候自动创建了索引和一些默认设置。将文档加入索引foreach ($lists as $row) { $params = [ 'body' => [ 'id' => $row['id'], 'title' => $row['title'], 'content' => $row['content'] ], 'id' => 'article_' . $row['id'], 'index' => 'articles_index', 'type' => 'articles_type' ]; $client->index($params); }从索引中获取文档$params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'articles_1' ]; $res = $client->get($params); print_r($res);从索引中删除文档$params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'articles_1' ]; $res = $client->delete($params); print_r($res);删除索引$params = [ 'index' => 'articles_index' ]; $res = $client->indices()->delete($params); print_r($res);创建索引$params['index'] = 'articles_index'; $params['body']['settings']['number_of_shards'] = 2; $params['body']['settings']['number_of_replicas'] = 0; $client->indices()->create($params);搜索$params = [ 'index' => 'articles_index', 'type' => 'articles_type', ]; $params['body']['query']['match']['content'] = 'Laravel'; $res = $client->search($params); print_r($res);
PHP如何使用 ElasticSearch 做搜索 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。在做搜索的时候想到了 ElasticSearch ,而且其也支持 PHP,所以就做了一个简单的例子做测试,感觉还不错,做下记录。环境php 8.0elasticsearch 8.2elasticsearch-php 8.2安装 elasticsearch下载源文件,解压,重新建一个用户,将目录的所属组修改为此用户,因为 elasticsearch 无法用 root 用户启动。wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3.tar.gz tar zxvf elasticsearch-8.2.3.tar.gz useradd elasticsearch password elasticsearch chown elasticsearch:elasticsearch elasticsearch-8.2.3 cd elasticsearch-8.2.3 ./bin/elasticsearch // 启动安装 PHP 扩展我这里使用的是 composer 安装 elasticsearch-php。在 composer.json 文件中加入 "elasticsearch/elasticsearch": "~8.2.3",执行 composer update。{ "require": { // ... "elasticsearch/elasticsearch": "~8.2.3" // ... } }测试例子创建表和测试数据我这里准备了一张文章表来进行测试,首先是建表,其次写入测试数据,准备工作完毕之后,就开始编辑测试用例。{ #创建articles表 create table articles( id int not null primary key auto_increment, title varchar(200) not null comment '标题', content text comment '内容' ); #插入文章内容 insert into articles(title, content) values ('Laravel 测试1', 'Laravel 测试文章内容1'),('Laravel 测试2', 'Laravel 测试文章内容2'),('Laravel 测试3', 'Laravel 测试文章内容3'); 从 Mysql 读取数据try { $db = new PDO('mysql:host=127.0.0.1;dbname=test', 'root',''); $sql = 'select * from articles'; $query = $db->prepare($sql); $query->execute(); $lists = $query->fetchAll(); print_r($lists); } catch (Exception $e) { echo $e->getMessage(); }实例化require './vendor/autoload.php'; use Elasticsearch\ClientBuilder; $client = ClientBuilder::create()->build();名词解释:索引相当于 MySQL 中的表,文档相当于 MySQL 中的行记录elasticsearch 的动态性质,在添加第一个文档的时候自动创建了索引和一些默认设置。将文档加入索引foreach ($lists as $row) { $params = [ 'body' => [ 'id' => $row['id'], 'title' => $row['title'], 'content' => $row['content'] ], 'id' => 'article_' . $row['id'], 'index' => 'articles_index', 'type' => 'articles_type' ]; $client->index($params); }从索引中获取文档$params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'articles_1' ]; $res = $client->get($params); print_r($res);从索引中删除文档$params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'articles_1' ]; $res = $client->delete($params); print_r($res);删除索引$params = [ 'index' => 'articles_index' ]; $res = $client->indices()->delete($params); print_r($res);创建索引$params['index'] = 'articles_index'; $params['body']['settings']['number_of_shards'] = 2; $params['body']['settings']['number_of_replicas'] = 0; $client->indices()->create($params);搜索$params = [ 'index' => 'articles_index', 'type' => 'articles_type', ]; $params['body']['query']['match']['content'] = 'Laravel'; $res = $client->search($params); print_r($res); -
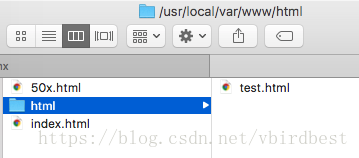
Nginx 的五大应用场景 一:HTTP服务器Nginx本身也是一个静态资源的服务器,当只有静态资源的时候,就可以使用Nginx来做服务器,如果一个网站只是静态页面的话,那么就可以通过这种方式来实现部署。1、 首先在文档根目录Docroot(/usr/local/var/www)下创建html目录, 然后在html中放一个test.html;2、 配置nginx.conf中的serveruser mengday staff; http { server { listen 80; server_name localhost; client_max_body_size 1024M; # 默认location location / { root /usr/local/var/www/html; index index.html index.htm; } } } 3、访问测试http://localhost/ 指向/usr/local/var/www/index.html, index.html是安装nginx自带的htmlhttp://localhost/test.html 指向/usr/local/var/www/html/test.html注意:如果访问图片出现403 Forbidden错误,可能是因为nginx.conf 的第一行user配置不对,默认是#user nobody;是注释的,linux下改成user root; macos下改成user 用户名 所在组; 然后重新加载配置文件或者重启,再试一下就可以了, 用户名可以通过who am i 命令来查看。4、指令简介server : 用于定义服务,http中可以有多个server块listen : 指定服务器侦听请求的IP地址和端口,如果省略地址,服务器将侦听所有地址,如果省略端口,则使用标准端口server_name : 服务名称,用于配置域名location : 用于配置映射路径uri对应的配置,一个server中可以有多个location, location后面跟一个uri,可以是一个正则表达式, / 表示匹配任意路径, 当客户端访问的路径满足这个uri时就会执行location块里面的代码root : 根路径,当访问http://localhost/test.html,“/test.html”会匹配到"/"uri, 找到root为/usr/local/var/www/html,用户访问的资源物理地址=root + uri = /usr/local/var/www/html + /test.html=/usr/local/var/www/html/test.htmlindex : 设置首页,当只访问server_name时后面不跟任何路径是不走root直接走index指令的;如果访问路径中没有指定具体的文件,则返回index设置的资源,如果访问http://localhost/html/ 则默认返回index.html5、location uri正则表达式. :匹配除换行符以外的任意字符? :重复0次或1次+ :重复1次或更多次* :重复0次或更多次\d :匹配数字^ :匹配字符串的开始$ :匹配字符串的结束{n} :重复n次{n,} :重复n次或更多次[c] :匹配单个字符c[a-z] :匹配a-z小写字母的任意一个(a|b|c) : 属线表示匹配任意一种情况,每种情况使用竖线分隔,一般使用小括号括括住,匹配符合a字符 或是b字符 或是c字符的字符串\ 反斜杠:用于转义特殊字符小括号()之间匹配的内容,可以在后面通过$1来引用,$2表示的是前面第二个()里的内容。正则里面容易让人困惑的是\转义特殊字符。二: 静态服务器在公司中经常会遇到静态服务器,通常会提供一个上传的功能,其他应用如果需要静态资源就从该静态服务器中获取。1、在/usr/local/var/www 下分别创建images和img目录,分别在每个目录下放一张test.jpghttp { server { listen 80; server_name localhost; set $doc_root /usr/local/var/www; # 默认location location / { root /usr/local/var/www/html; index index.html index.htm; } location ^~ /images/ { root $doc_root; } location ~* \.(gif|jpg|jpeg|png|bmp|ico|swf|css|js)$ { root $doc_root/img; } } } 自定义变量使用set指令,语法 set 变 量 名 值 ; 引 用 使 用 变量名 值; 引用使用 变量名值;引用使用变量名; 这里自定义了doc_root变量。静态服务器location的映射一般有两种方式:使用路径,如 /images/ 一般图片都会放在某个图片目录下,使用后缀,如 .jpg、.png 等后缀匹配模式访问http://localhost/test.jpg 会映射到$doc_root/img访问http://localhost/images/test.jpg 当同一个路径满足多个location时,优先匹配优先级高的location,由于^~ 的优先级大于 ~, 所以会走/images/对应的location常见的location路径映射路径有以下几种:= 进行普通字符精确匹配。也就是完全匹配。^~ 前缀匹配。如果匹配成功,则不再匹配其他location。~ 表示执行一个正则匹配,区分大小写~* 表示执行一个正则匹配,不区分大小写/xxx/ 常规字符串路径匹配/ 通用匹配,任何请求都会匹配到location优先级当一个路径匹配多个location时究竟哪个location能匹配到时有优先级顺序的,而优先级的顺序于location值的表达式类型有关,和在配置文件中的先后顺序无关。相同类型的表达式,字符串长的会优先匹配。以下是按优先级排列说明:等号类型(=)的优先级最高。一旦匹配成功,则不再查找其他匹配项,停止搜索。^~类型表达式,不属于正则表达式。一旦匹配成功,则不再查找其他匹配项,停止搜索。正则表达式类型(~ ~*)的优先级次之。如果有多个location的正则能匹配的话,则使用正则表达式最长的那个。常规字符串匹配类型。按前缀匹配。/ 通用匹配,如果没有匹配到,就匹配通用的优先级搜索问题:不同类型的location映射决定是否继续向下搜索等号类型、^~类型:一旦匹配上就停止搜索了,不会再匹配其他location了正则表达式类型(~ ~*),常规字符串匹配类型/xxx/ : 匹配到之后,还会继续搜索其他其它location,直到找到优先级最高的,或者找到第一种情况而停止搜索location优先级从高到底:(location =) > (location 完整路径) > (location ^~ 路径) > (location ,* 正则顺序) > (location 部分起始路径) > (/)location = / { # 精确匹配/,主机名后面不能带任何字符串 / [ configuration A ] } location / { # 匹配所有以 / 开头的请求。 # 但是如果有更长的同类型的表达式,则选择更长的表达式。 # 如果有正则表达式可以匹配,则优先匹配正则表达式。 [ configuration B ] } location /documents/ { # 匹配所有以 /documents/ 开头的请求,匹配符合以后,还要继续往下搜索。 # 但是如果有更长的同类型的表达式,则选择更长的表达式。 # 如果有正则表达式可以匹配,则优先匹配正则表达式。 [ configuration C ] } location ^~ /images/ { # 匹配所有以 /images/ 开头的表达式,如果匹配成功,则停止匹配查找,停止搜索。 # 所以,即便有符合的正则表达式location,也不会被使用 [ configuration D ] } location ~* \.(gif|jpg|jpeg)$ { # 匹配所有以 gif jpg jpeg结尾的请求。 # 但是 以 /images/开头的请求,将使用 Configuration D,D具有更高的优先级 [ configuration E ] } location /images/ { # 字符匹配到 /images/,还会继续往下搜索 [ configuration F ] } location = /test.htm { root /usr/local/var/www/htm; index index.htm; } 注意:location的优先级与location配置的位置无关 三: 反向代理反向代理应该是Nginx使用最多的功能了,反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。简单来说就是真实的服务器不能直接被外部网络访问,所以需要一台代理服务器,而代理服务器能被外部网络访问的同时又跟真实服务器在同一个网络环境,当然也可能是同一台服务器,端口不同而已。反向代理通过proxy_pass指令来实现。启动一个Java Web项目,端口号为8081server { listen 80; server_name localhost; location / { proxy_pass http://localhost:8081; proxy_set_header Host $host:$server_port; # 设置用户ip地址 proxy_set_header X-Forwarded-For $remote_addr; # 当请求服务器出错去寻找其他服务器 proxy_next_upstream error timeout invalid_header http_500 http_502 http_503; } } 当我们访问localhost的时候,就相当于访问 localhost:8081了四:负载均衡负载均衡也是Nginx常用的一个功能,负载均衡其意思就是分摊到多个操作单元上进行执行,例如Web服务器、FTP服务器、企业关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。简单而言就是当有2台或以上服务器时,根据规则随机的将请求分发到指定的服务器上处理,负载均衡配置一般都需要同时配置反向代理,通过反向代理跳转到负载均衡。而Nginx目前支持自带3种负载均衡策略,还有2种常用的第三方策略。负载均衡通过upstream指令来实现。1. RR(round robin :轮询 默认):每个请求按时间顺序逐一分配到不同的后端服务器,也就是说第一次请求分配到第一台服务器上,第二次请求分配到第二台服务器上,如果只有两台服务器,第三次请求继续分配到第一台上,这样循环轮询下去,也就是服务器接收请求的比例是 1:1, 如果后端服务器down掉,能自动剔除。轮询是默认配置,不需要太多的配置同一个项目分别使用8081和8082端口启动项目upstream web_servers { server localhost:8081; server localhost:8082; } server { listen 80; server_name localhost; #access_log logs/host.access.log main; location / { proxy_pass http://web_servers; # 必须指定Header Host proxy_set_header Host $host:$server_port; } } 访问地址仍然可以获得响应 http://localhost/api/user/login?username=zhangsan&password=111111 ,这种方式是轮询的2. 权重指定轮询几率,weight和访问比率成正比, 也就是服务器接收请求的比例就是各自配置的weight的比例,用于后端服务器性能不均的情况,比如服务器性能差点就少接收点请求,服务器性能好点就多处理点请求。upstream test { server localhost:8081 weight=1; server localhost:8082 weight=3; server localhost:8083 weight=4 backup; } 示例是4次请求只有一次被分配到8081上,其他3次分配到8082上。backup是指热备,只有当8081和8082都宕机的情况下才走80833. ip_hash上面的2种方式都有一个问题,那就是下一个请求来的时候请求可能分发到另外一个服务器,当我们的程序不是无状态的时候(采用了session保存数据),这时候就有一个很大的很问题了,比如把登录信息保存到了session中,那么跳转到另外一台服务器的时候就需要重新登录了,所以很多时候我们需要一个客户只访问一个服务器,那么就需要用iphash了,iphash的每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。upstream test { ip_hash; server localhost:8080; server localhost:8081; } 4. fair(第三方)按后端服务器的响应时间来分配请求,响应时间短的优先分配。这个配置是为了更快的给用户响应upstream backend { fair; server localhost:8080; server localhost:8081; } 5. url_hash(第三方)按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。 在upstream中加入hash语句,server语句中不能写入weight等其他的参数,hash_method是使用的hash算法upstream backend { hash $request_uri; hash_method crc32; server localhost:8080; server localhost:8081; } 以上5种负载均衡各自适用不同情况下使用,所以可以根据实际情况选择使用哪种策略模式,不过fair和url_hash需要安装第三方模块才能使用。五:动静分离动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路。upstream web_servers { server localhost:8081; server localhost:8082; } server { listen 80; server_name localhost; set $doc_root /usr/local/var/www; location ~* \.(gif|jpg|jpeg|png|bmp|ico|swf|css|js)$ { root $doc_root/img; } location / { proxy_pass http://web_servers; # 必须指定Header Host proxy_set_header Host $host:$server_port; } error_page 500 502 503 504 /50x.html; location = /50x.html { root $doc_root; } } 六:其他1.return指令返回http状态码 和 可选的第二个参数可以是重定向的URLlocation /permanently/moved/url { return 301 http://www.example.com/moved/here; } 2. rewrite指令重写URI请求 rewrite,通过使用rewrite指令在请求处理期间多次修改请求URI,该指令具有一个可选参数和两个必需参数。 第一个(必需)参数是请求URI必须匹配的正则表达式。 第二个参数是用于替换匹配URI的URI。 可选的第三个参数是可以停止进一步重写指令的处理或发送重定向(代码301或302)的标志location /users/ { rewrite ^/users/(.*)$ /show?user=$1 break; } 3. error_page指令使用error_page指令,您可以配置NGINX返回自定义页面以及错误代码,替换响应中的其他错误代码,或将浏览器重定向到其他URI。 在以下示例中,error_page指令指定要返回404页面错误代码的页面(/404.html)。error_page 404 /404.html; 4. 日志访问日志:需要开启压缩 gzip on; 否则不生成日志文件,打开log_format、access_log注释log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /usr/local/etc/nginx/logs/host.access.log main; gzip on; 5. deny 指令# 禁止访问某个目录 location ~* \.(txt|doc)${ root $doc_root; deny all; } 6. 内置变量nginx的配置文件中可以使用的内置变量以美元符$开始,也有人叫全局变量。其中,部分预定义的变量的值是可以改变的。$args : #这个变量等于请求行中的参数,同$query_string$content_length : 请求头中的Content-length字段。$content_type : 请求头中的Content-Type字段。$document_root : 当前请求在root指令中指定的值。$host : 请求主机头字段,否则为服务器名称。$http_user_agent : 客户端agent信息$http_cookie : 客户端cookie信息$limit_rate : 这个变量可以限制连接速率。$request_method : 客户端请求的动作,通常为GET或POST。$remote_addr : 客户端的IP地址。$remote_port : 客户端的端口。$remote_user : 已经经过Auth Basic Module验证的用户名。$request_filename : 当前请求的文件路径,由root或alias指令与URI请求生成。$scheme : HTTP方法(如http,https)。$server_protocol : 请求使用的协议,通常是HTTP/1.0或HTTP/1.1。$server_addr : 服务器地址,在完成一次系统调用后可以确定这个值。$server_name : 服务器名称。$server_port : 请求到达服务器的端口号。$request_uri : 包含请求参数的原始URI,不包含主机名,如:”/foo/bar.php?arg=baz”。$uri : 不带请求参数的当前URI,$uri不包含主机名,如”/foo/bar.html”。$document_uri : 与$uri相同
-
Linux简介及最常用命令 Linux是目前应用最广泛的服务器操作系统,基于Unix,开源免费,由于系统的稳定性和安全性,市场占有率很高,几乎成为程序代码运行的最佳系统环境。linux不仅可以长时间的运行我们编写的程序代码,还可以安装在各种计算机硬件设备中,如手机、路由器等,Android程序最底层就是运行在linux系统上的。一、linux的目录结构/ 下级目录结构bin (binaries)存放二进制可执行文件sbin (super user binaries)存放二进制可执行文件,只有root才能访问etc (etcetera)存放系统配置文件usr (unix shared resources)用于存放共享的系统资源home 存放用户文件的根目录root 超级用户目录dev (devices)用于存放设备文件lib (library)存放跟文件系统中的程序运行所需要的共享库及内核模块mnt (mount)系统管理员安装临时文件系统的安装点boot 存放用于系统引导时使用的各种文件tmp (temporary)用于存放各种临时文件var (variable)用于存放运行时需要改变数据的文件二、linux常用命令命令格式:命令 -选项 参数 (选项和参数可以为空)如:ls -la /usr2.1 操作文件及目录2.2 系统常用命令2.3 压缩解压缩2.4 文件权限操作linux文件权限的描述格式解读r 可读权限,w可写权限,x可执行权限(也可以用二进制表示 111 110 100 --> 764)第1位:文件类型(d 目录,- 普通文件,l 链接文件)第2-4位:所属用户权限,用u(user)表示第5-7位:所属组权限,用g(group)表示第8-10位:其他用户权限,用o(other)表示第2-10位:表示所有的权限,用a(all)表示三、linux系统常用快捷键及符号命令四、vim编辑器vi / vim是Linux上最常用的文本编辑器而且功能非常强大。只有命令,没有菜单,下图表示vi命令的各种模式的切换图。4.1 修改文本4.2 定位命令4.3 替换和取消命令4.4 删除命令4.5 常用快捷键
-
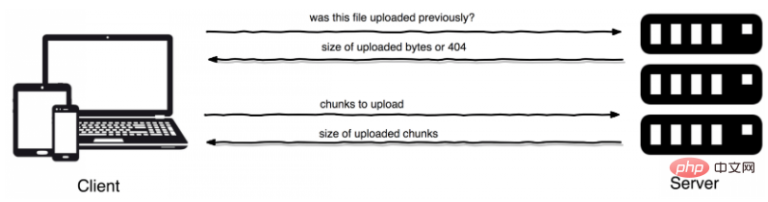
大文件断点续传,用PHP怎么实现 在现代网站应用中,上传文件是非常常见的。在任何语言中,通过使用一些工具,都可以实现文件上传的功能。但是,如果处理大文件上传的需求,还是有点麻烦的。假如你此时正在上传一个很大的文件,大约一个小时过去了,进度是 90%。突然断网了或者浏览器崩溃了,上传的程序退出,你要再全部重新来过。真的很不爽,对不对?还有更让人郁闷的是,如果你的网速很慢,那么,无论你重来多少次,你都不可能上传成功。在 PHP 中,我们可以尝试利用 tus 协议的断点续传功能来解决这个问题。什么是 tus?Tus 是一个基于 HTTP 的 文件断点续传开放协议。断点续传的意思是不管是用户自行中断,还是由于网络等原因的意外中断,都可以从中断的地方继续上传,而不用重新开始。Tus 协议是在 2017 年5月被 Vimeo 采用的。为什么用 tus?引用 Vimeo 的博客:我们之所以决定用 tus,是因为它能以简洁开放的形式,将文件上传的过程标准化。这种标准化有利于 API 的开发者更加专注于应用本身的逻辑,而非文件上传的过程。使用这种方式上传的另一个好处是,你可以在笔记本上开始上传文件,然后又转到手机或者其他设备继续上传同一个文件,这可以极大地提升用户体验。开始第一步,composer安装依赖。$ composer require ankitpokhrel/tus-phptus-php 是用于 tus 断点续传协议 v1.0.0 的一个的纯 PHP 框架,完美实现了 服务端与客户端的交互 。更新: 现在 Vimeo 官方 PHP 库 的 v3 用的是 TusPHP。创建一个处理请求的服务端你可以像下面这样创建一个服务端.// server.php $server = new \TusPhp\Tus\Server('redis'); $response = $server->serve(); $response->send(); exit(0); // 退出当前 PHP 进程你需要配置你的服务器以便能对特定的终端进行响应。如果使用 Nginx 的话你可以像下面这样配置:# nginx.conf location /files { try_files $uri $uri/ /path/to/server.php?$query_string; }假设我们服务端的 URL 是 http://server.tus.local. 因此,基于我们上面的 Nginx 配置,我们可以通过 http://server.tus.local/files. 来访问到我们的 tus 终端.如果你是用类似于 Laravel 的框架,那么你就不需要在配置文件里定义这些了, 可以直接定义路由来访问 tus 的基础端点。使用 tus-php 客户端处理上传服务器到位后,客户端可以块的形式上传文件。让我们首先创建一个简单的 HTML 表单来获取用户的输入。<form action="upload.php" method="post" enctype="multipart/form-data"> <input type="file" name="tus_file" id="tus-file" /> <input type="submit" value="Upload" /> </form>提交表单后,我们需要按照几个步骤来处理上传。创建一个 tus-php 客户端对象// Tus client $client = new \TusPhp\Tus\Client('http://server.tus.local');上面代码中的第一个参数是你的 tus 服务器地址。2. 使用文件元数据初始化客户端为了确保上传文件的唯一性,我们需要给每个上传的文件以唯一标识。这样在文件中断后续传的时候,服务器就可以很清晰地辨识出,哪几个片段是属于同一个文件得。这个标识码可以自己指定,也可以由系统生成。// 设置标识码和文件元数据 $client->setKey($uploadKey) ->file($_FILES['tus_file']['tmp_name'], 'your file name');如果不想指定标识码,可以这样写,由系统会自动生成:$client->file($_FILES['tus_file']['tmp_name'], 'your file name');$uploadKey = $client->getKey(); // Unique upload key3. 分块上传文件// $chunkSize 是以字节为单位的,例如 5000000 等于 5 MB $bytesUploaded = $client->upload($chunkSize);当你想要续传下一块的时候,就可以带上同样的标识码参数来续传。// 在下一个请求中续传文件 $bytesUploaded = $client->setKey($uploadKey)->upload($chunkSize);文件全部上传完成后,默认情况下,服务器会使用 sha256 来校验文件总和,以确保不会有丢失的文件。使用 tus-js-client 客户端处理文件上传tus 协议的团队还开发了一个模块化的文件上传插件 Uppy。这个插件可以在官方 tus-js-client 和 tus-php 服务器之间建立连接。也就是说我们可以使用 php 配合 js 来实现文件上传了。uppy.use(Tus, { endpoint: 'https://server.tus.local/files/', // 你的 tus 服务器 resume: true, autoRetry: true, retryDelays: [0, 1000, 3000, 5000]})分块上传tus-php 服务器支持 concatenation 扩展,可以把多次上传的文件合为一个文件。因此,我们可以在客户端支持并行上传以及非连续的分块文件上传。使用 tus-php 实现分块上传tus-partial-upload.php<?php // 文件唯一标识码 $uploadKey = uniqid(); $client->setKey($uploadKey)->file('/path/to/file', 'chunk_a.ext'); // 从第 1000 个字节开始上传 10000 字节 $bytesUploaded = $client->seek(1000)->upload(10000); $chunkAkey = $client->getKey(); // 从 第 0 个字节开始上传 10000 字节 $bytesUploaded = $client->setFileName('chunk_b.ext')->seek(0)->upload(1000); $chunkBkey = $client->getKey(); // 从第 11000 个字节 (10000 + 1000) 开始上传剩余的字节 $bytesUploaded = $client->setFileName('chunk_c.ext')->seek(11000)->upload(); $chunkCkey = $client->getKey(); // 把分块上传的文件组合起来 $client->setFileName('actual_file.ext')->concat($uploadKey, $chunkAkey, $chunkBkey, $chunkCkey);分块上传的完整例子https://github.com/ankitpokhrel/tus-php/tree/master/example/partial
-
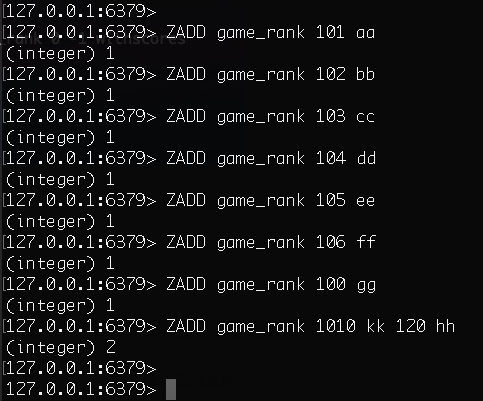
Redis的一大场景:排行榜实时更新 Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数 (score) 却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O (1)。集合中最大的成员数为 2^32 - 1^ (4294967295, 每个集合可存储 40 多亿个成员)。有序集合首先是集合,其成员(member)具有唯一性,其次,每个成员关联了一个分数(score),使得成员可以按照分数排序。需求描述设想在一个游戏中,有上百万的玩家数据,如果现在需要你根据玩家的经验值整理一个前 10 名的排行榜,你会怎么做呢?一般的做法是写一条类似下面这条 sql 语句的方式来获取:select * from game_socre order by score desc limit 0,20这种方式在数据量较小的情况下可行,但是在数据量大的情况下查询速度将变慢,特别是还需要联表查询时,速度下降的就更明显了。实现这时你可以考虑使用 redis 来实现这个功能。实现这个功能主要用到的 redis 数据类型是 redis 的有序集合 zset。zset 是 set 类型的一个扩展,比原有的类型多了一个顺序属性。此属性在每次插入数据时会自动调整顺序值,保证 value 值按照一定顺序连续排列。主要的实现思路是:1、在一个新的玩家参与到游戏中时,在 redis 中的 zset 中新增一条记录(记录内容看具体的需求)score 为 02、当玩家的经验值发生变化时,修改该玩家的 score 值3、使用 redis 的 ZREVRANGE 方法获取排行榜返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递减 (从大到小) 来排列。具有相同 score 值的成员按字典序的反序排列。除了成员按 score 值递减的次序排列这一点外,ZREVRANGE 命令的其他方面和 ZRANGE 命令一样。redis 127.0.0.1:6379> ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUEN1、数据准备2、获取 score 高分 top8 排名 (ZREVRANGE 为降序,ZRANGE 为升序)3、查看用户 ee 的实际排名 (ZREVRANK 为降序,ZRANK 为升序)、实时分数进一步需求需要实现最近的 24 小时用户积分排行榜,并统计前 10 名的玩家和积分实现主要的实现思路是:利用 ZADD 按小时划分添加用户的积分信息,然后用 ZUNIONSTORE 并集实现 24 小时的游戏积分总和,实现 “24 小时排行榜”;(如果有更好的思路,能够在下方留言不吝赐教一下就更好了)ZUNIONSTORE destination numkeys key [key ...]Redis Zunionstore 命令计算给定的一个或多个有序集的并集,其中给定 key 的数量必须以 numkeys 参数指定,并 ? ? 将该并集(结果集)储存到 destination 。默认情况下,结果集中某个成员的分数值是所有给定集下该成员分数值之和 。可能碰到的问题1、相同分数问题Redis 在遇到分数相同时是按照集合成员自身的字典顺序来排序,这里即是按照”user2″和”user3″这两个字符串进行排序,以逆序排序的话 user3 自然排到了前面。要解决这个问题,我们可以考虑在分数中加入时间戳,计算公式为:带时间戳的分数 = 实际分数*10000000000 + (9999999999 – timestamp)timestamp 我们采用系统提供的 time () 函数,也就是 1970 年 1 月 1 日以来的秒数,我们采用 32 位的时间戳(这能坚持到 2038 年),由于 32 位时间戳是 10 位十进制整数(最大值 4294967295);所以我们让时间戳占据低 10 位(十进制整数),实际分数则扩大 10^10 倍,然后把两部分相加的结果作为 zset 的分数。考虑到要按时间倒序排列,所以时间戳这部分需要颠倒一下,这便是用 9999999999 减去时间戳的原因。当我们要读取玩家实际分数时,只需去掉后 10 位即可。初步看起来这个方案还不错,但这里面有两个问题。第一个问题是小问题,采用秒为时间戳可能区分度还不够,如果同一秒出现两个分数相同的仍然会出现前面的问题,当然我们可以选择精度更高的时间戳,但在实际场景中,同一秒谁排前面已经无关紧要。第二个问题是大问题,因为 Redis 的分数类型采用的是 double,64 位双精度浮点数只有 52 位有效数字,它能精确表达的整数范围为 - 2^53 到 2^53,最高只能表示 16 位十进制整数(最大值为 9007199254740992,其实连 16 位也不能完整表示)。这就是说,如果前面时间戳占了 10 位的话,分数就只剩下 6 位了,这对于某些排行榜分数来说是不够用的。我们可以考虑缩减时间戳位数,比如从 2015 年 1 月 1 日开始计时,但这仍然增加不了几位。或者减少区分度,以分钟、小时来作为时间戳单位。如果 Redis 的分数类型为 int64,我们就没有上面的烦恼。说到这里,其实 Redis 真应该再额外提供一个 int64 类型的 ZSet,但目前只能是幻想,除非自己改其源码。