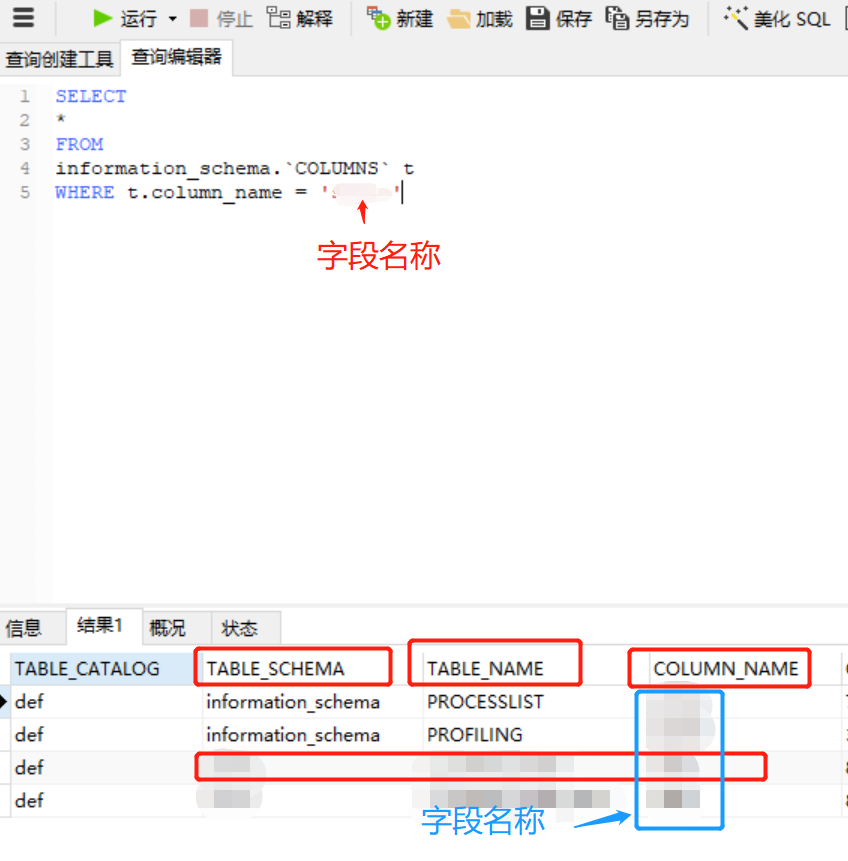
搜索到
57
篇与
quhe.net
的结果
-

-
Mysql批量更新的四种方式 逐条update的弊端最近做一个需求,更新2w条数据,一个一个update去更新的,结果花了30分钟,这样性能上很差,也容易阻塞,所以就找了一些MySQL批量更新的方式,在此记录一下方法一;replace into{message type="warning" content="这种更新会将其它字段更新为默认值,因为它是先将重复记录删掉再更新,如果更新的字段不全会将缺失的字段置为缺省值,谨慎使用"/}replace into `user` (id,age) values (1,'2'),(2,'3'),(3,'4'),(4,'98'); -- > 时间: 0.038s 方法二:insert into [table] values… on duplicate key update (Mysql独有的语法)。这种方式应该也是删掉记录,再更新,但是保存的原来的其它字段数据,所以其它字段不会改变insert into `user`(id,age) values (1,'5'),(2,'7'),(3,'2'),(4,'198') on duplicate key update age=values(age) -- > > 时间: 0.017s 方法三:创建临时表创建临时表,将更新数据插入临时表,再执行更新,需要有 建表权限DROP TABLE if EXISTS tmp; -- > 时间: 0.016s create temporary table tmp(id int(4) primary key,age varchar(50)); -- > 时间: 0.01s insert into tmp values (1,'13'), (2,'16'),(3,'18'),(4,'18'); -- > 时间: 0.009s update `user`, tmp set `user`.age=tmp.age where `user`.id=tmp.id; -- > 时间: 0.022s 方法四:使用MySQL自带批量更新语句update `user` set age = CASE id WHEN 1 THEN '22' WHEN 2 THEN '22' WHEN 3 THEN '22' WHEN 4 THEN '22' END WHERE id IN(1,2,3,4); -- > 时间: 0.015s update (表名) set (更新字段) = case (被更新字段) when (被更新字段值) then (更新字段值)... end where (被更新字段) in((被更新字段值)...) {card-describe title="举例说明"}set age = CASE id WHEN 1 THEN ‘22’简单来说就是以id为查询条件,当id=1时更新age=22,后面的where语句只是为了提高sql的执行效率,先过滤需要修改的记录然后再更新。{/card-describe}
-
PHP实现拖拽排序功能接口 思路先分析一个场景,假如有一个页面有十条数据,所谓的拖拽就是在这十条数据来来回回的拖,但是每次拖动都会影响到其他数据例如把最后一条拖到最前面,那么后面九条就自动往后移,反之也是,嗯~~~ 先想象一下,排序号是固定的,就好像有十把椅子,每个椅子都是固定在那里的,移动的是上面的人,这样就不会影响到其他页面的数据了而且每个人换的也是之前其他人的桌椅号码,这样也不用去想到底要加多少才能排在哪里。代码实现//$ids 这十条数据的id集合,逗号隔开的字符串 //$oldIndex 原始位置,从0开始算 //$newIndex 要拖动到的位置 function dragSort($ids,$oldIndex,$newIndex) { //保证查找出来的数据跟前台提交的顺序一致,这里要用到mysql的 order by field() //id 主键 sort 排序值 $sql = "select id,sort from 表名字 where id in ($ids) order by field(id, " . $ids . ") "; $list = "这里省略,就是数据库返回的二维数组数据记录"; //id集合 $idArr = []; //排序集合 $sortArr = []; foreach ($list as $item) { $idArr[] = $item['id']; $sortArr[] = $item['sort']; } /* 或者 $idArr=array_column($list, 'id'); $sortArr=array_column($list, 'sort'); */ //记录要拖动记录的id $oldValue = $idArr[$oldIndex]; //删除这个要拖动的id unset($idArr[$oldIndex]); //插入新的位置,并自动移位 array_splice($idArr, $newIndex, 0, $oldValue); //重新设置排序 $set = []; for ($i = 0; $i < count($idArr); $i++) { $set[$i]['id'] = $idArr[$i]; $set[$i]['sort'] = $sortArr[$i]; } //保存到数据库省略① } {callout color="#f0ad4e"}@数据库批量更新四种方式{/callout}
-
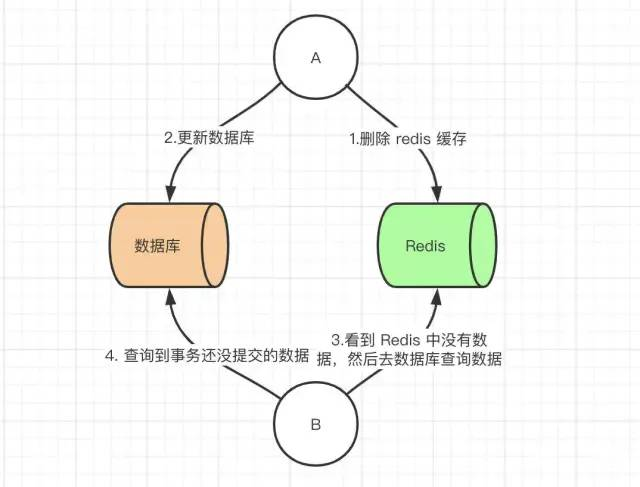
如何保证缓存与数据库双写时的数据一致性 如何保证缓存与数据库双写时的数据一致性?在做系统优化时,想到了将数据进行分级存储的思路。因为在系统中会存在一些数据,有些数据的实时性要求不高,比如一些配置信息。基本上配置了很久才会变一次。而有一些数据实时性要求非常高,比如订单和流水的数据。所以这里根据数据要求实时性不同将数据分为三级。第1级:订单数据和支付流水数据;这两块数据对实时性和精确性要求很高,所以不添加任何缓存,读写操作将直接操作数据库。第2级:用户相关数据;这些数据和用户相关,具有读多写少的特征,所以我们使用redis进行缓存。第3级:支付配置信息;这些数据和用户无关,具有数据量小,频繁读,几乎不修改的特征,所以我们使用本地内存进行缓存。但是只要使用到缓存,无论是本地内存做缓存还是使用 redis 做缓存,那么就会存在数据同步的问题,因为配置信息缓存在内存中,而内存时无法感知到数据在数据库的修改。这样就会造成数据库中的数据与缓存中数据不一致的问题。接下来就讨论一下关于保证缓存和数据库双写时的数据一致性。解决方案那么我们这里列出来所有策略,并且讨论他们优劣性。先更新数据库,后更新缓存先更新数据库,后删除缓存先更新缓存,后更新数据库先删除缓存,后更新数据库先更新数据库,后更新缓存这种场景一般是没有人使用的,主要原因是在更新缓存那一步,为什么呢?因为有的业务需求缓存中存在的值并不是直接从数据库中查出来的,有的是需要经过一系列计算来的缓存值,那么这时候后你要更新缓存的话其实代价是很高的。如果此时有大量的对数据库进行写数据的请求,但是读请求并不多,那么此时如果每次写请求都更新一下缓存,那么性能损耗是非常大的。举个例子比如在数据库中有一个值为 1 的值,此时我们有 10 个请求对其每次加一的操作,但是这期间并没有读操作进来,如果用了先更新数据库的办法,那么此时就会有十个请求对缓存进行更新,会有大量的冷数据产生,如果我们不更新缓存而是删除缓存,那么在有读请求来的时候那么就会只更新缓存一次。先更新缓存,后更新数据库这一种情况应该不需要我们考虑了吧,和第一种情况是一样的。先删除缓存,后更新数据库该方案也会出问题,具体出现的原因如下。此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)请求 A 会先删除 Redis 中的数据,然后去数据库进行更新操作此时请求 B 看到 Redis 中的数据时空的,会去数据库中查询该值,补录到 Redis 中但是此时请求 A 并没有更新成功,或者事务还未提交那么这时候就会产生数据库和 Redis 数据不一致的问题。如何解决呢?其实最简单的解决办法就是延时双删的策略。但是上述的保证事务提交完以后再进行删除缓存还有一个问题,就是如果你使用的是 Mysql 的读写分离的架构的话,那么其实主从同步之间也会有时间差。此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)请求 A 更新操作,删除了 Redis请求主库进行更新操作,主库与从库进行同步数据的操作请 B 查询操作,发现 Redis 中没有数据去从库中拿去数据此时同步数据还未完成,拿到的数据是旧数据此时的解决办法就是如果是对 Redis 进行填充数据的查询数据库操作,那么就强制将其指向主库进行查询。先更新数据库,后删除缓存问题:这一种情况也会出现问题,比如更新数据库成功了,但是在删除缓存的阶段出错了没有删除成功,那么此时再读取缓存的时候每次都是错误的数据了。此时解决方案就是利用消息队列进行删除的补偿。具体的业务逻辑用语言描述如下:请求 A 先对数据库进行更新操作在对 Redis 进行删除操作的时候发现报错,删除失败此时将Redis 的 key 作为消息体发送到消息队列中系统接收到消息队列发送的消息后再次对 Redis 进行删除操作但是这个方案会有一个缺点就是会对业务代码造成大量的侵入,深深的耦合在一起,所以这时会有一个优化的方案,我们知道对 Mysql 数据库更新操作后再 binlog 日志中我们都能够找到相应的操作,那么我们可以订阅 Mysql 数据库的 binlog 日志对缓存进行操作。总结每种方案各有利弊,比如在第二种先删除缓存,后更新数据库这个方案我们最后讨论了要更新 Redis 的时候强制走主库查询就能解决问题,那么这样的操作会对业务代码进行大量的侵入,但是不需要增加的系统,不需要增加整体的服务的复杂度。最后一种方案我们最后讨论了利用订阅 binlog 日志进行搭建独立系统操作 Redis,这样的缺点其实就是增加了系统复杂度。其实每一次的选择都需要我们对于我们的业务进行评估来选择,没有一种技术是对于所有业务都通用的。没有最好的,只有最适合我们的。
-
用PHP与Redis实现单据锁,防止并发重复写入数据 一、何为单据锁:在整个供应链系统中,会有很多种单据(采购单、入库单、到货单、运单等等),在涉及写单据数据的接口时(增删改操作),即使前端做了相关限制,还是有可能因为网络或异常操作产生并发重复调用的情况,导致对相同单据做相同的处理;为了防止这种情况对系统造成异常影响,我们通过Redis实现了一个简单的单据锁,每个请求需先获取锁才能执行业务逻辑,执行结束后才会释放锁;保证了同一单据的并发重复操作请求只有一个请求可以获取到锁(依赖Redis的单线程),是一种悲观锁的设计;注:Redis锁在我们的系统中一般只用于解决并发重复请求的情况,对于非并发的的重复请求一般会去数据库或日志校验数据的状态,两种机制结合起来才能保证整个链路的可靠。二、加锁机制:主要依赖Redis setnx指令实现:但使用setnx有一个问题,即setnx指令不支持设置过期时间,需要使用expire指令另行为key设置超时时间。这样整个加锁操作就不是一个原子性操作,有可能存在setnx加锁成功,但因程序异常退出导致未成功设置超时时间,在不及时解锁的情况下,有可能会导致死锁(即使业务场景中不会出现死锁,无用的key一直常驻内存也不是很好的设计);这种情况可以使用Redis事务解决,把setnx与expire两条指令作为一个原子性操作执行,但这样做相对而言会比较麻烦,好在Redis 2.6.12之后版本,Redis set指令支持了nx、ex模式,并支持原子化地设置过期时间:三、加锁实现(完整测试代码会贴在最后):/** * 加单据锁 * @param int $intOrderId 单据ID * @param int $intExpireTime 锁过期时间(秒) * @return bool|int 加锁成功返回唯一锁ID,加锁失败返回false */ public static function addLock($intOrderId, $intExpireTime = self::REDIS_LOCK_DEFAULT_EXPIRE_TIME) { //参数校验 if (empty($intOrderId) || $intExpireTime <= 0) { return false; } //获取Redis连接 $objRedisConn = self::getRedisConn(); //生成唯一锁ID,解锁需持有此ID $intUniqueLockId = self::generateUniqueLockId(); //根据模板,结合单据ID,生成唯一Redis key(一般来说,单据ID在业务中系统中唯一的) $strKey = sprintf(self::REDIS_LOCK_KEY_TEMPLATE, $intOrderId); //加锁(通过Redis setnx指令实现,从Redis 2.6.12开始,通过set指令可选参数也可以实现setnx,同时可原子化地设置超时时间) $bolRes = $objRedisConn->set($strKey, $intUniqueLockId, ['nx', 'ex'=>$intExpireTime]); //加锁成功返回锁ID,加锁失败返回false return $bolRes ? $intUniqueLockId : $bolRes; }四、解锁机制:解锁即比对加锁时的唯一lock id,如果比对成功,则删除key;需要注意的是,解锁整个过程中同样需要保证原子性,这里依赖redis的watch与事务实现;WATCH命令可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行。监控一直持续到EXEC命令(事务中的命令是在EXEC之后才执行的,所以在MULTI命令后可以修改WATCH监控的键值)五、解锁实现(完整测试代码会贴在最后):/** * 解单据锁 * @param int $intOrderId 单据ID * @param int $intLockId 锁唯一ID * @return bool */ public static function releaseLock($intOrderId, $intLockId) { //参数校验 if (empty($intOrderId) || empty($intLockId)) { return false; } //获取Redis连接 $objRedisConn = self::getRedisConn(); //生成Redis key $strKey = sprintf(self::REDIS_LOCK_KEY_TEMPLATE, $intOrderId); //监听Redis key防止在【比对lock id】与【解锁事务执行过程中】被修改或删除,提交事务后会自动取消监控,其他情况需手动解除监控 $objRedisConn->watch($strKey); if ($intLockId == $objRedisConn->get($strKey)) { $objRedisConn->multi()->del($strKey)->exec(); return true; } $objRedisConn->unwatch(); return false; }六、附整体测试代码(此代码仅为简易版本)<?php /** * Class Lock_Service 单据锁服务 */ class Lock_Service { /** * 单据锁redis key模板 */ const REDIS_LOCK_KEY_TEMPLATE = 'order_lock_%s'; /** * 单据锁默认超时时间(秒) */ const REDIS_LOCK_DEFAULT_EXPIRE_TIME = 86400; /** * 加单据锁 * @param int $intOrderId 单据ID * @param int $intExpireTime 锁过期时间(秒) * @return bool|int 加锁成功返回唯一锁ID,加锁失败返回false */ public static function addLock($intOrderId, $intExpireTime = self::REDIS_LOCK_DEFAULT_EXPIRE_TIME) { //参数校验 if (empty($intOrderId) || $intExpireTime <= 0) { return false; } //获取Redis连接 $objRedisConn = self::getRedisConn(); //生成唯一锁ID,解锁需持有此ID $intUniqueLockId = self::generateUniqueLockId(); //根据模板,结合单据ID,生成唯一Redis key(一般来说,单据ID在业务中系统中唯一的) $strKey = sprintf(self::REDIS_LOCK_KEY_TEMPLATE, $intOrderId); //加锁(通过Redis setnx指令实现,从Redis 2.6.12开始,通过set指令可选参数也可以实现setnx,同时可原子化地设置超时时间) $bolRes = $objRedisConn->set($strKey, $intUniqueLockId, ['nx', 'ex'=>$intExpireTime]); //加锁成功返回锁ID,加锁失败返回false return $bolRes ? $intUniqueLockId : $bolRes; } /** * 解单据锁 * @param int $intOrderId 单据ID * @param int $intLockId 锁唯一ID * @return bool */ public static function releaseLock($intOrderId, $intLockId) { //参数校验 if (empty($intOrderId) || empty($intLockId)) { return false; } //获取Redis连接 $objRedisConn = self::getRedisConn(); //生成Redis key $strKey = sprintf(self::REDIS_LOCK_KEY_TEMPLATE, $intOrderId); //监听Redis key防止在【比对lock id】与【解锁事务执行过程中】被修改或删除,提交事务后会自动取消监控,其他情况需手动解除监控 $objRedisConn->watch($strKey); if ($intLockId == $objRedisConn->get($strKey)) { $objRedisConn->multi()->del($strKey)->exec(); return true; } $objRedisConn->unwatch(); return false; } /** * Redis配置:IP */ const REDIS_CONFIG_HOST = '127.0.0.1'; /** * Redis配置:端口 */ const REDIS_CONFIG_PORT = 6379; /** * 获取Redis连接(简易版本,可用单例实现) * @param string $strIp IP * @param int $intPort 端口 * @return object Redis连接 */ public static function getRedisConn($strIp = self::REDIS_CONFIG_HOST, $intPort = self::REDIS_CONFIG_PORT) { $objRedis = new Redis(); $objRedis->connect($strIp, $intPort); return $objRedis; } /** * 用于生成唯一的锁ID的redis key */ const REDIS_LOCK_UNIQUE_ID_KEY = 'lock_unique_id'; /** * 生成锁唯一ID(通过Redis incr指令实现简易版本,可结合日期、时间戳、取余、字符串填充、随机数等函数,生成指定位数唯一ID) * @return mixed */ public static function generateUniqueLockId() { return self::getRedisConn()->incr(self::REDIS_LOCK_UNIQUE_ID_KEY); } } //test $res1 = Lock_Service::addLock('666666'); var_dump($res1);//返回lock id,加锁成功 $res2 = Lock_Service::addLock('666666'); var_dump($res2);//false,加锁失败 $res3 = Lock_Service::releaseLock('666666', $res1); var_dump($res3);//true,解锁成功 $res4 = Lock_Service::releaseLock('666666', $res1); var_dump($res4);//false,解锁失败